



人類嘗試著讓電腦擁有與人類相同的思考能力,在1958年,感知機(Perceptron)這個啟蒙概念就被提出,但由於只是個初期理論,未能實際投入到應用上,電腦科學家不斷參考人腦神經元運作方式,在20世紀末逐漸將必要的理論完備。正當要一展身手的時候,電腦科學家確發現自己低估人腦是多麼精密且處理能力強大,以當時的運算能力,訓練出一個模型不僅曠日費時,而且不一定能夠一次就能夠成功,因此這個理論的流派又再度沉寂了一陣子。在摩爾理論基礎中,除了CPU外的另一個運算元件GPU發展下,讓大量並行運算的速度與成本達到合理的範圍後,做了些調整再以新的名稱重新展現在世人面前,其結果成功奪取科技圈的目光,也就是最近常聽到的深度學習(Deep learning)。
銷售與客服兩個單位,是企業與顧客面對面最直接的媒介,而其中的客服平時是要面對客戶疑問、疑難排解、資訊查詢、訂單處理,一個客服人員同一時間裡,只能面對一個客戶,可以稱的上是個人力與產品知識密集的單位。電腦擅長迅速處理精準的問題,人類之所以會拿「冷冰冰」這個詞來形容電腦,是因電腦只能回應夠精準的問題,沒有被設計者考慮進去的情境,一概被列為不精準問題,電腦無法提供你相對應的答案,使用者轉而尋求9「為您轉接客服專員」的幫助,這也是為何在電腦發明了將近八十年,真人客服依然屹立不搖,以及大多數話機上的12顆按鈕中,9永遠是最乾淨明亮的根本原因。
在資訊領域裡,讓電腦去暸解與分析人類使用文字符號的學科稱為自然語言處理(Natural Language Processing),自然語言處理也是一門擁有長久發展歷史的技術。在全世界的數據中,大約有21%的資料屬於結構化資料,客服中心處理的語音與文字對話,正是屬於佔大部份的非結構化資料,這是一座尚未開採的金礦,而自然語言處理就像是一盞明燈,賦予機器一部份理解人類語言功能,進而有能力去挖掘非結構化資料。「人分成兩種,一種好看,一種難看,你剛好介於兩者之間,屬於好難看的」,如果以情緒字典下去計算,可以算出「好難看」是反向情緒沒錯,但語言經過人類社會的千錘百鍊,其抽像程度非常之高。常見的網路用語「啊不就好棒棒」是一種富有弦外之音的說法,連外國人都無法理解一堆正向的詞擺在一起,結果會產生負向的意思,更何況是電腦,可見沒有一套的公式或規則就能夠描述文字間的情緒。以往的自然語言處理,靠的就是這些所謂的高品質字典以及特徵工程,雖然投入大量的人力與時間去研究,但得到的結果卻往往不盡理想。適逢這個資訊爆炸的世代,從網路上取得帶有情緒標註的資料變得容易許多,深度學習能在數據驅動(Data-Driven)下,自動從大量數據中萃取出一些特徵,來評斷一段話的情感傾向,或是將一篇文本分類。只要模型參數設計的好,訓練的資料夠完整,就能夠得到一個效果不錯的分析模型。
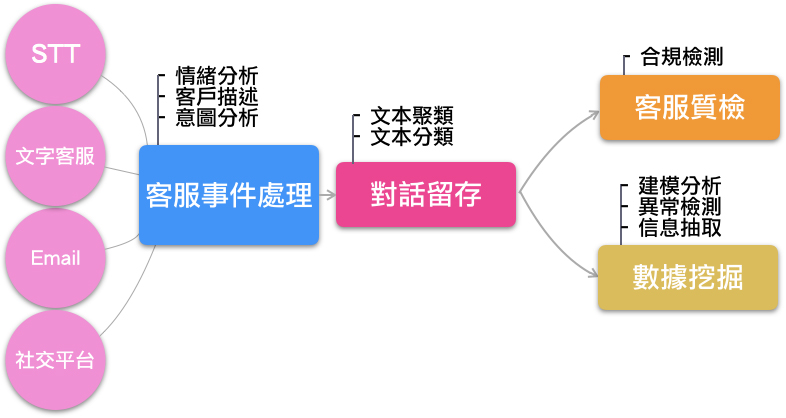
現代客服產業應用裡,與客戶溝通的渠道,因智慧型的裝置興起而趨於多樣化,線上文字客服、Email、社交平台就能夠傳訊息與客服人員進行客戶服務,而這些傳送的文字對話本來就屬於自然語言處理的範圍。語音客服不管是透過一般的電話,或者是即時通訊軟體,語音訊號利用STT(Speech to text)轉譯成文本後,也能夠使用自然語言來進行處理。而客服事件處理進行時,以自然語言為工具,讓客服人員更暸解客戶後,提供更適當的服務。已結束的服務,能用更聰明的方式將這些對話保留,以供往後更快速的進行檢視或利用。而如同前面所說的,對話過程裡留下來非結構化資料,如何用自然語言轉換為結構化資訊,也是必要的過程。
客服事件處理
客戶每次進線分配到的通常不是同一個客服人員,所以客服人員與客戶都是素未謀面,如果提供以下這些方法,讓客服人員對客戶多一點的暸解,能夠讓客戶感到舒服的狀況下,得到這每一次的客服服務
- 情緒分析: 讓客戶的情緒在可被量測下進行監控,一方面能讓客服人員更加的感同身受,另一方面也能暸解客戶願意以及不願意接觸的話題。
- 客戶描述: 一個經驗老道的客服人員,經過一定程度的對話後,就可以掌握客戶個性大致的個性樣貌,以及字裡行間透露出的重要訊息,可以使用客戶描述讓這項功能成為每席客服人員的「標配」技能。而這位客戶的樣貌資訊,可以在每位接待客服人員裡被共享,在與客戶接觸越久後,樣貌輪廓也就會更完整。
對話留存
在客戶務服進行一段時間後,留存的資料也就會越來越多而形成大數據,每一份資料都會成為滋養深度學習的來源。但數據量一大還能提供往後的檢視,以及暸解資料的輪廓,都是大數據架構下的必要條件。
- 文本聚類: 機器學習能在未提供更多的標注下,利用文本的裡的特徵,將各個文本在高維度空間中進行分群。而數據管理者就能夠在群聚的結果裡,觀測出目前持有數據的樣貌,進一步分析能夠獲取更多的資訊。
- 文本分類: 相較於文本聚類,文本分類更明確知道分群的意圖,在以監督或半監督的狀態下,讓資料分門別類。在往後的檢視或分析中,能夠取單一類或多個類別進行處理,可以大量的減少運算資源以及處理時間。
客服質檢
在客服產業裡,非常注重的就是事後的客服質檢,這攸關於客服品質的好與壞,如上面所說的,深度學習使用於自然言處理中,在抽像的語意概念裡以及詞語間的相似度關聯判斷能力,都較舊有的技術強,因此在質檢評分裡,能夠得到更客觀精準的評分。而用電腦來進行質檢,在處理速度上,以及可以24小時不間斷的工作,與人工質檢相比,更容易達到「全質檢」的目標。
數據挖掘
在這個數據淘金的時代,企業能擁數據量就像是原油儲備量,經過提煉的數據,能成為企業向前邁進的動力來源。一個懂的怎麼使用數據的公司,和一個只存放卻不知道怎麼去運用的公司,在往後的經營上的差異,只會越來越明顯。
- 建模分析:與情緒分析類似,我們可以依靠數據去建立分類或評分的模型,不同以往硬梆梆規則式模型(Rule-Based),深度學習模型能夠提供更有關聯更深層的分析,甚至能夠讓模型達到自適應能力,而不用靠一個領域專家去手動調整模型或增減規則。
- 異常檢測:其原理與建模分析相似,不同在於分析結果出來後,依造異常程度狀況,而採取不同通知程序,對管理者進行通知,或產生異常報表供往後檢視。
- 信息抽取:這是個從非結構化資料轉換為結構化資料的過程,因為有這個過程,讓往後的搜尋或者機器學習建模,會變的更加的容易。
鑽石與黃金埋藏在地底下數萬年,直到被發現開採出來價值依舊存在,而數據礦與他們不同的是,數據礦會是具有時效性的,其價值會隨著時間慢慢的「氧化」,所以趁著手上的礦還新鮮的時候,準備好工具,當個快樂的礦工。
作者:研發部 Joe